안녕하세요! 오늘은 Kubernetes에서 GPU 환경을 구축하는 방법에 대해 자세히 알아보려고 합니다. 저도 처음에 이 과정을 진행할 때 많은 어려움이 있었는데요, GPU Operator를 통해 GPU를 사용할 수 있게 하는 방법을 단계별로 정리해보았습니다. 😊

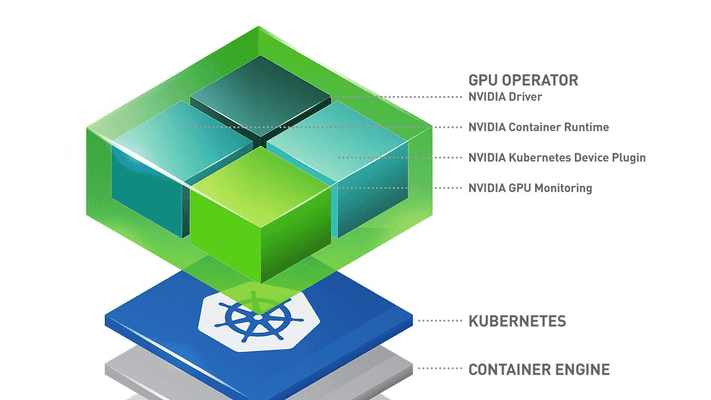
GPU Operator는 NVIDIA에서 제공하는 강력한 도구로, Kubernetes 클러스터에서 GPU를 쉽게 관리할 수 있도록 도와줍니다. 이 Operator를 사용하면 GPU 리소스를 효율적으로 활용할 수 있으며, 다양한 컴포넌트들이 자동으로 배포되어 관리됩니다.
Helm Chart 다운로드 및 내부 살펴보기
먼저, Helm Chart를 다운로드해야 합니다. Helm은 Kubernetes에서 패키지 관리 도구로, GPU Operator를 설치하는 데 매우 유용합니다. Helm Chart를 다운로드한 후, 내부 구조를 살펴보면 다음과 같은 주요 컴포넌트들이 포함되어 있습니다.
- NVIDIA Driver
- Container Runtime
- Kubernetes Device Plugin
- GPU Monitoring
이러한 컴포넌트들은 GPU 리소스를 관리하는 데 필수적입니다.
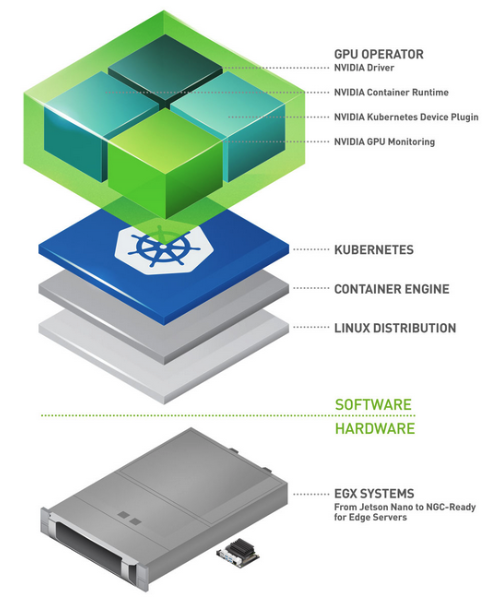
Helm Chart는 Kubernetes 애플리케이션을 패키징하고 관리하는 데 사용되는 패키지 관리 시스템입니다. 쉽게 말해, Helm Chart는 여러 Kubernetes 리소스(Deployment, Service, ConfigMap 등)를 하나의 패키지로 묶어두어 배포와 관리를 간편하게 해줍니다.
Helm Chart 다운로드 방법
Helm Chart를 다운로드하는 방법은 크게 두 가지가 있습니다.1. Helm Repository에서 다운로드
- Helm Repository 등록:
helm repo add <repository-name> <repository-url>
- Chart 다운로드:
2. GitHub 등에서 직접 다운로드
- GitHub에서 Chart 소스 코드 다운로드: 원하는 Chart의 GitHub 레포지토리로 이동하여 ZIP 파일로 다운로드하거나, Git 명령어를 사용하여 Clone합니다.
Helm Chart는 일반적으로 다음과 같은 디렉토리 구조를 가지고 있습니다.
컴포넌트들의 역할과 동작 과정
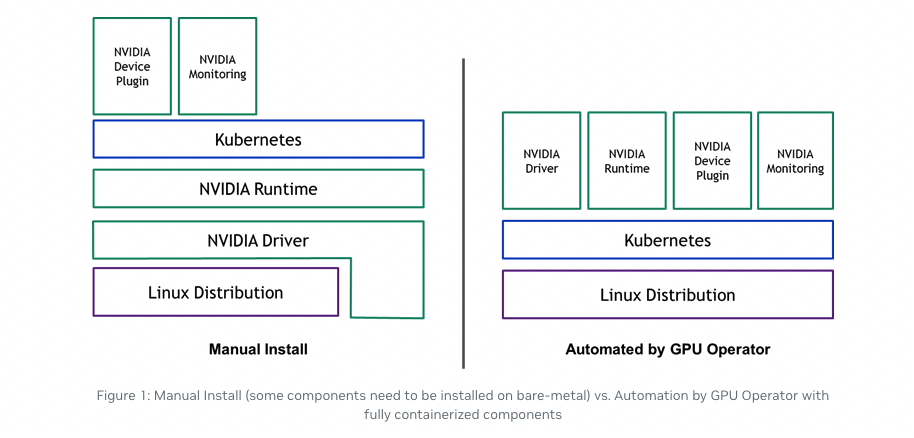
각 컴포넌트의 역할을 이해하는 것이 중요합니다. NVIDIA Driver는 GPU와 소프트웨어 간의 인터페이스 역할을 하며, Container Runtime은 컨테이너를 실행하는 데 필요한 환경을 제공합니다. Kubernetes Device Plugin은 Kubernetes가 GPU를 인식하고 사용할 수 있도록 도와줍니다. 마지막으로, GPU Monitoring은 GPU의 상태를 모니터링하여 성능을 최적화하는 데 기여합니다.
GPU 노드에 테인트 추가하기
GPU 노드에 테인트를 추가하는 과정은 GPU 리소스를 특정 파드에만 할당할 수 있도록 도와줍니다. 이를 통해 리소스의 낭비를 줄이고, 필요한 곳에만 GPU를 사용할 수 있게 됩니다.
Helm Chart 배포하기
이제 Helm Chart를 배포해보겠습니다. Helm을 사용하여 GPU Operator를 설치하면, 필요한 모든 컴포넌트가 자동으로 배포됩니다. 이 과정에서 발생할 수 있는 오류를 미리 확인하고, 적절한 조치를 취하는 것이 중요합니다.
Binpack 스케줄링으로 리소스 사용 효율화하기
Binpack 스케줄링은 리소스를 효율적으로 사용하는 방법 중 하나입니다. 이 방법을 사용하면, GPU 리소스를 최대한 활용할 수 있으며, 불필요한 리소스 낭비를 줄일 수 있습니다.
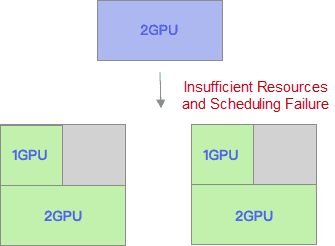
Resource Fragmentation 문제
리소스 단편화는 GPU 리소스를 효율적으로 사용하지 못하게 하는 주요 원인 중 하나입니다. 이를 해결하기 위해서는 스케줄러의 동작 과정을 이해하고, 적절한 스코어링 정책을 설정해야 합니다.
스케줄러의 동작 과정 이해하기
Kubernetes의 스케줄러는 파드를 적절한 노드에 배치하는 역할을 합니다. 이 과정에서 GPU 리소스의 상태를 고려하여 최적의 노드를 선택하게 됩니다.
스케줄러의 스코어링 정책 설정하기
스케줄러의 스코어링 정책을 설정하면, GPU 리소스를 보다 효율적으로 사용할 수 있습니다. 이를 통해 특정 파드가 GPU를 사용할 수 있는 최적의 노드를 선택할 수 있습니다.
커스텀 스케줄러 만들고 배포하기
필요에 따라 커스텀 스케줄러를 만들어 배포할 수 있습니다. 이를 통해 특정 요구사항에 맞는 스케줄링을 구현할 수 있습니다.
Binpack 스케줄링 확인하기
Binpack 스케줄링이 제대로 작동하는지 확인하는 과정도 필요합니다. 이를 통해 리소스 사용의 효율성을 검증할 수 있습니다.
OPA로 SchedulerName 검증하기
OPA(Open Policy Agent)를 사용하여 SchedulerName을 검증할 수 있습니다. 이를 통해 스케줄링 정책이 올바르게 적용되었는지 확인할 수 있습니다.
Dynamic Admission Controller와 OPA
Dynamic Admission Controller와 OPA를 함께 사용하면, Kubernetes 클러스터의 보안을 강화할 수 있습니다. 이를 통해 리소스의 사용을 보다 세밀하게 관리할 수 있습니다.
Validation Admission Webhook을 위한 Rego 스크립트
Rego 스크립트를 작성하여 Validation Admission Webhook을 설정할 수 있습니다. 이를 통해 클러스터에 배포되는 리소스의 유효성을 검증할 수 있습니다.
OPA 배포하기
OPA를 클러스터에 배포하여 정책을 적용할 수 있습니다. 이를 통해 리소스 관리의 효율성을 높일 수 있습니다.
작동 확인하기
배포한 OPA가 제대로 작동하는지 확인하는 과정도 필요합니다. 이를 통해 정책이 올바르게 적용되었는지 검증할 수 있습니다.
리소스 모니터링하기
리소스를 모니터링하는 것은 매우 중요합니다. 이를 통해 GPU 리소스의 사용 현황을 파악하고, 필요한 조치를 취할 수 있습니다.
Prometheus와 Grafana 배포하기
Prometheus와 Grafana를 배포하여 리소스를 모니터링할 수 있습니다. 이를 통해 GPU 리소스의 상태를 시각적으로 확인할 수 있습니다.
GPU Metric을 위한 ServiceMonitor 배포하기
ServiceMonitor를 배포하여 GPU 메트릭을 수집할 수 있습니다. 이를 통해 GPU 리소스의 사용 현황을 보다 세밀하게 모니터링할 수 있습니다.
Grafana에 대시보드 추가하기
마지막으로, Grafana에 대시보드를 추가하여 GPU 리소스의 상태를 시각적으로 확인할 수 있습니다. 이를 통해 리소스 관리의 효율성을 높일 수 있습니다.
이렇게 Kubernetes에서 GPU 환경을 구축하는 방법에 대해 알아보았습니다. 각 단계에서 주의해야 할 점과 팁을 공유했으니, 여러분도 이 과정을 통해 효율적인 GPU 환경을 구축하시길 바랍니다! 😊




댓글 없음:
댓글 쓰기