
가. 파이프라인 기법
파이프라인 기법은 CPU의 사용을 극대화하기 위해 명령을 겹쳐서 실행하는 방법으로, 하나의 CPU 코어에 여러 개의 스레드를 사용하는 것입니다. 일반적으로는 한 명령어를 처리하기 위해서는 처리 4단계를 모두 마치고 다음 명령어를 실행하지만, 파이프라인 기법에서는 명령어 처리 단계마다 독립적인 구성을 통해 각 단계가 쉬지 않고 명령어를 처리할 수 있습니다. 이를 통해 CPU의 처리량과 효율성을 향상시킬 수 있습니다. 예를 들어, 파이프라인에는 명령어를 가져오는 단계(instruction fetch), 디코딩하는 단계(instruction decode), 실행하는 단계(execution), 그리고 결과를 기록하는 단계(write-back)가 포함될 수 있습니다. 이러한 단계는 동시에 여러 명령어를 처리함으로써 CPU의 성능을 최적화합니다. 최신 기술 및 프로세서 디자인에서는 파이프라인 기법을 계속해서 발전시키고 있으며, 병렬성과 효율성을 높이는데 중요한 역할을 합니다.

- 위와 같이 명령어 처리 단계를 4단계로 나누면 동시에 처리되는 명령어 최대 개수는 4개입니다. 하지만, 이러한 파이프라인 기법에는 여러 가지 문제가 있다.
1) 데이터 위험
파이프라인 기법을 사용할 때 발생할 수 있는 한 가지 문제는 데이터 위험(data hazards)입니다. 데이터 의존성 때문에 발생하는 이 문제는 한 명령어가 필요로 하는 데이터가 이전 명령어에 의해 아직 사용 중이거나 준비되지 않은 상태일 때 발생합니다. 예를 들어, 한 명령어가 계산한 결과를 다음 명령어가 사용해야 하는 경우가 이에 해당합니다. 이 경우에는 파이프라인을 효율적으로 유지하기 위해 명령어 단계를 지연시켜야 합니다. 이 지연은 명령어 실행을 일시 중단하거나 기다리는 것으로, 데이터 의존성을 해결하고 파이프라인의 안정성을 유지합니다. 이러한 지연은 파이프라인의 성능을 저하시킬 수 있지만, 데이터 위험을 피하기 위해 필요한 조치입니다. 이러한 문제를 해결하기 위해 고급 파이프라인 기술이나 예측적인 실행 등의 기술이 발전하고 있습니다.
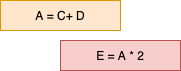
2) 제어 위험
또 다른 파이프라인 기법에서 발생할 수 있는 문제는 제어 위험(control hazards)입니다. 이는 분기 명령문(if 문이나 goto 문 등)이 프로그램 카운터 값을 갑자기 변경함으로써 발생하는 문제입니다. 일반적으로 프로그램은 순차적으로 실행된다고 가정하지만, 분기 명령문이 예상과 다른 위치로 이동할 경우, 현재 파이프라인에 있는 명령어들은 불필요해지게 됩니다.
이러한 문제를 해결하기 위해 분기 예측(branch prediction)이나 분기 지연(branch delay) 등의 기술이 사용됩니다. 분기 예측은 분기가 발생할 것으로 예상되는지를 사전에 예측하여 그에 따라 파이프라인을 조정합니다. 이를 통해 파이프라인이 불필요하게 비어있는 상태를 피하고, 유효한 명령어를 계속해서 처리할 수 있습니다. 또한 분기 지연은 분기 명령을 실행하기 전에 다음 명령을 실행하여 파이프라인을 유지하는 방법입니다. 이를 통해 분기로 인한 지연을 최소화하고 파이프라인의 효율성을 유지할 수 있습니다.
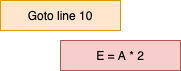
3) 구조 위험
구조 위험(structural hazards)은 파이프라인에서 발생하는 또 다른 문제로, 서로 다른 명령어가 동시에 같은 하드웨어 자원에 접근하려고 할 때 발생합니다. 이는 하드웨어 자원의 한정된 사용으로 인해 발생하는 문제로, 충돌이 발생하면 프로그램이 비정상적으로 작동하거나 종료될 수 있습니다.
구조 위험은 해결하기 어려운 문제 중 하나로 알려져 있습니다. 하드웨어 자원을 병렬로 사용할 수 있는 방법이 제한되어 있기 때문에 충돌을 완전히 피하기는 어렵습니다. 따라서 구조 위험을 해결하려면 하드웨어 디자인을 최적화하고 파이프라인을 설계할 때 자원 충돌을 최소화해야 합니다. 그러나 완전한 해결책은 아니며, 때로는 구조 위험을 최소화하기 위해 프로그램의 구조를 변경하거나 특별한 예외 처리를 구현해야 할 수도 있습니다.
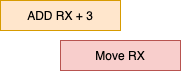
나. 슈퍼스칼라 기법
슈퍼스칼라 기법은 파이프라인을 처리할 수 있는 코어를 여러 개 구성하여 복수의 명령어가 동시에 실행되도록 하는 방식입니다. 이 기법은 파이프라인 기법과 유사하지만, 보다 병렬성을 높이는 특징이 있습니다. 슈퍼스칼라 프로세서에서는 두 개 이상의 실행 유닛(execution unit)을 가지고 있어 동시에 여러 명령어를 실행할 수 있습니다. 이를 통해 단일 스레드 내에서도 더 많은 명령어들을 병렬로 처리할 수 있어 성능을 향상시킬 수 있습니다.
슈퍼스칼라 기법을 사용하는 CPU는 파이프라인 기법과 마찬가지로 처리되는 명령어들이 상호 의존성 없이 독립적이어야 하며, 이를 위해 하드웨어와 소프트웨어 레벨에서 명령어의 스케줄링이나 예측적인 실행 등의 기술이 사용됩니다. 오늘날 대부분의 고성능 CPU는 슈퍼스칼라 기법을 채택하여 병렬성을 극대화하고 성능을 향상시키고 있습니다.
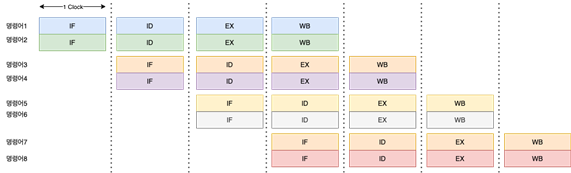
다. 슈퍼파이프라인 기법
슈퍼파이프라인 기법은 파이프라인 기법을 강화한 것으로, 파이프라인의 각 단계를 더 세분화하여 한 클록 내에 여러 명령어를 처리할 수 있는 방식입니다. 파이프라인 기법에서는 한 클록마다 하나의 명령어를 실행하는 것에 비해, 슈퍼파이프라인 기법에서는 각 단계를 더 잘게 쪼개어 한 클록 내에 여러 명령어를 처리할 수 있습니다. 이를 통해 병렬 처리 능력을 높이고 실행 속도를 더욱 향상시킬 수 있습니다.
슈퍼파이프라인은 각 단계를 더 작은 단위로 분할하여 파이프라인의 깊이(depth)를 더 깊게 만듭니다. 이는 각 단계가 더 빨리 처리되도록 하여 클록 주기를 줄이고, 따라서 더 빠른 명령어 실행을 가능하게 합니다. 하지만, 파이프라인의 깊이가 깊어질수록 파이프라인을 채우는 데 필요한 회로와 레지스터의 양이 증가하고, 또한 파이프라인 끝단에서 발생하는 지연이 증가할 수 있습니다. 이러한 이유로 슈퍼파이프라인을 설계할 때에는 균형있는 파이프라인 깊이와 성능 간의 트레이드오프를 고려해야 합니다.
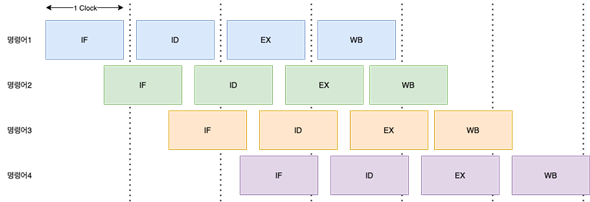
라. 슈퍼파이프라인 슈퍼스칼라 기법
슈퍼파이프라인 슈퍼스칼라 기법은 슈퍼파이프라인과 슈퍼스칼라 두 가지 기법을 결합한 것입니다. 이는 파이프라인을 더욱 세분화하여 한 클록 내에 여러 명령어를 처리할 수 있게끔 하고, 동시에 여러 개의 실행 유닛을 가진 슈퍼스칼라 기법을 사용하여 여러 명령어를 동시에 실행하는 방식입니다.
슈퍼파이프라인 기법에서는 파이프라인의 각 단계를 세분화하여 더 많은 단계로 나누어 처리 속도를 높이는 반면, 슈퍼스칼라 기법에서는 여러 개의 실행 유닛을 사용하여 동시에 여러 명령어를 실행하는 방식입니다. 이 두 가지 기법을 결합함으로써 명령어의 병렬 실행과 동시에 파이프라인의 세분화를 동시에 수행할 수 있습니다.
슈퍼파이프라인 슈퍼스칼라 기법은 더 높은 처리량과 성능 향상을 제공할 수 있으나, 이를 위해서는 복잡한 하드웨어 구조와 설계가 필요합니다. 또한 이러한 기법을 사용하는 CPU는 전력 소모가 높을 수 있으며, 열 문제와 같은 다른 고려 사항도 고려해야 합니다. 이러한 이유로 슈퍼파이프라인 슈퍼스칼라 기법은 고성능 컴퓨팅 및 서버용 CPU에서 주로 사용되는 경향이 있습니다.
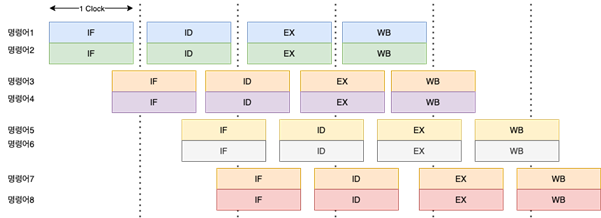
마. VLIW 기법
VLIW(very long instruction word) 기법은 병렬 처리를 하기 위해 소프트웨어적인 방법을 사용하는 기법입니다. 이 방법은 CPU가 병렬 처리를 지원하지 않을 때 유용하게 사용됩니다.
VLIW에서는 동시에 수행할 수 있는 명령어들을 컴파일러가 추출하고 하나의 명령어로 압축하여 실행합니다. 이것은 매우 긴(instruction word) 명령어를 형성하는 것을 의미합니다. 즉, 여러 개의 동작을 포함하는 하나의 명령어를 생성하고, 이를 실행하는 것입니다.
이러한 명령어는 컴파일 시에 이미 병렬 처리를 위해 준비되어 있기 때문에, 실행 시에는 별다른 병렬 처리 지원이 필요하지 않습니다. 대신에, CPU는 단순히 하나의 명령어를 읽고 실행하면 됩니다.
VLIW 기법은 병렬성을 활용하기 위해 하드웨어의 복잡성을 줄일 수 있어서 전력 소모나 발열 문제를 해결하는 데 도움이 될 수 있습니다. 그러나 효율적인 VLIW 코드를 생성하기 위해서는 적절한 컴파일러가 필요하며, 명령어 간의 의존성을 최소화하기 위해 주의가 필요합니다. VLIW는 특히 임베디드 시스템 및 특정 형태의 병렬 처리가 필요한 응용 프로그램에서 주로 사용됩니다.
바. 파이프라인 유형별 비교(– T: 명령어 실행 시간, k: 파이프라인 단계, N 실행 명령어 수)
| 유형 | 개념도 | 특징/성능 |
| 파이프라인 | 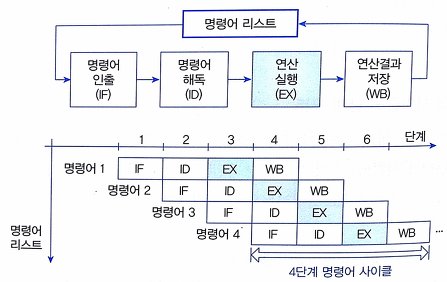 | – Micro Instruction 기반 병렬처리 – Pt = k + (N – 1) |
| 슈퍼 파이프라인 | 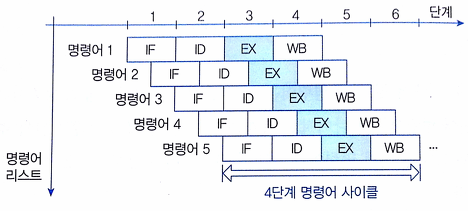 | – CPU Clock Degree 기반 파이프라인 – SPt = k + 1/n * (N – 1) n: CPU Clock degree (1 Clock 당 수행 횟수) |
SCRIPT https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-9114794658383389 SCRIPT
(adsbygoogle = window.adsbygoogle || []).push({});
| ||
| 슈퍼 스칼라 |  | – 다수 기능 유닛기반 파이프라인 중첩 – SSt = k + (N – m)/m m: 파이프라인 중첩 수 |
| 슈퍼 파이프라인 슈퍼스칼라 | 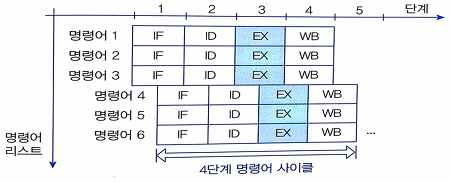 | – CPU Clock Degree기반 파이프라인 중첩 – SPSSt = k + (N – m)/(m * n) |
| VLIW (Explicitly Parallel Instruction Computing) | 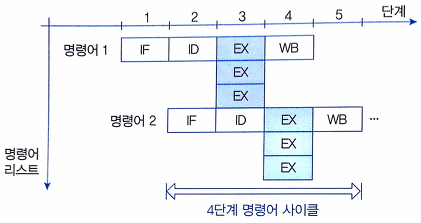 | – 동시 수행 명령어를 컴파일러 수준으로 추출 – Instruction 압축 |




댓글 없음:
댓글 쓰기